
在 GPU 渲染领域,TBR(Tile-Based Rendering,基于图块的渲染)是一种渲染架构和技术。以下是关于 TBR 以及移动端广泛使用它的原因介绍:
TBR 的基本原理
TBR 将渲染画面分割成一个个较小的图块(Tile),而不是像传统的立即模式渲染(Immediate Mode Rendering)那样直接处理整个画面。GPU 在渲染时,会按顺序依次处理每个图块。在处理单个图块时,GPU 会在片上缓存(如 L1、L2 Cache)中完成该图块内像素的各种计算,包括顶点处理、像素着色、深测试、颜色混合等操作。只有当一个图块处理完成后,才会将最终结果写入到系统内存(如 LPDDR)中,用于显示或后续处理。
这种架构会将 FrameBuffer 划分为多个方形的 Tile 块,渲染 Tile 时先将绘制结果存放在容量小但速度快的 On-chip Memory(或称 Graphics Memory,GMEM)中,Tile 绘制完毕后再拷贝至 FrameBuffer。由于将拷贝过程分为了多次,虽然牺牲了部分效率,但是大幅降低了带宽,解决了最麻烦的带宽和功耗问题,因为访问 DRAM 内存是一种非常昂贵的带宽消耗。
传统渲染与 TBR 的 FrameBuffer 交互对比
在传统的立即模式渲染(如桌面端早期 GPU 常用的方式)中,GPU 处理画面时不分割图块,而是直接对整个屏幕(FrameBuffer)进行逐像素操作:
- 渲染过程中,GPU 需要频繁从系统内存(或显存)的 FrameBuffer 中读取已有像素数据(如深度值、颜色值),进行计算后再写回 FrameBuffer;
- 例如,渲染一个复杂场景时,远处的物体、近处的物体、半透明物体需要多次覆盖同一区域的像素,每次操作都要与 FrameBuffer 进行 "读 - 改 - 写" 交互。
而 TBR(基于图块的渲染)则完全不同:
- 先将屏幕分割成多个小图块(如 128x128 像素),逐个处理每个图块;
- 每个图块的所有渲染操作(顶点处理、像素着色、深度测试等)全部在片上缓存(如 GMEM 或 L2 Cache)中完成,直到整个图块处理完毕,才将最终结果一次性拷贝到系统内存的 FrameBuffer 中。
"牺牲部分效率" 的原因:多次拷贝的额外开销
"牺牲效率" 主要体现在数据传输的 "次数增加" 上:
- 传统方式对整个画面的渲染是 "一次性" 与 FrameBuffer 交互(虽然过程中存在多次读写,但逻辑上是对同一帧缓冲的连续操作);
- 而 TBR 需要对每个图块单独进行 "最终结果拷贝"—— 假设屏幕被分成 100 个图块,就需要执行 100 次拷贝操作(从片上缓存到 FrameBuffer)。
这些额外的拷贝操作会带来少量控制层面的开销(如每次拷贝需要启动传输通道、验证数据完整性等),理论上比 "一次性处理整个画面" 的总操作步骤更多,因此牺牲了部分 "纯效率"(单位时间内的操作次数)。
"大幅降低带宽和功耗" 的核心逻辑
尽管存在多次拷贝的开销,但 TBR 对带宽和功耗的优化效果远超过效率损失,这是由移动端硬件限制(低带宽、电池供电)决定的:
1. 降低带宽:减少与系统内存的 "无效交互"
-
传统渲染的痛点:GPU 在处理像素时,需要频繁从 FrameBuffer(系统内存)中读取数据(如已渲染的像素深度、颜色),但这些数据中大部分是临时的、会被后续像素覆盖的。例如,渲染一个遮挡关系复杂的场景时,远处物体的像素可能刚被写入 FrameBuffer,就被近处物体的像素覆盖,之前的 "读 - 写" 操作完全是无效带宽消耗。
-
TBR 的优化:每个图块的所有计算(包括深度测试、颜色混合等)都在片上缓存中完成。片上缓存的容量足以容纳一个图块的所有临时数据(如该图块内的深度缓冲、颜色缓冲),因此:
- 图块内部的像素覆盖、叠加操作,只需要在片上缓存中进行 "内部读写",无需与系统内存的 FrameBuffer 交互;
- 只有当图块最终结果确定后,才将 "最终像素值" 一次性写入 FrameBuffer,避免了传统方式中 "临时数据反复读写内存" 的无效带宽消耗。
举例:假设一个图块有 1000 个像素,传统方式可能需要对这 1000 个像素进行 10 次覆盖(每次都读写内存),总传输量为 1000×10=10000 单位;而 TBR 只需在最后传输 1000 单位的最终结果,带宽消耗直接降为 1/10。
2. 降低功耗:减少 "高功耗的内存交互"
- 硬件特性:芯片内部的片上缓存(如 L2 Cache、GMEM)的读写功耗远低于系统内存(LPDDR) (通常相差 10 倍以上)。这是因为内存交互需要通过外部总线传输,而片上缓存是芯片内部的快速存储,无需额外的电力驱动数据远距离传输。
- TBR 的优势:将图块的大部分渲染操作限制在片上缓存中,大幅减少了与系统内存的交互次数和数据量。例如,一个 3D 游戏场景的渲染中,TBR 可以将内存交互量降低 60% 以上,对应的功耗也会成比例减少 —— 这对电池容量有限的移动端设备至关重要(直接延长续航)。
移动端的取舍逻辑
TBR 通过 "分多次拷贝图块结果",虽然增加了少量拷贝次数(牺牲部分效率),但通过将临时数据限制在片上缓存、只传输最终结果,彻底解决了传统渲染中 "临时数据反复读写内存" 导致的带宽浪费和高功耗问题。
对于移动端设备(内存带宽低、依赖电池供电),"带宽和功耗" 是比 "少量效率损失" 更核心的瓶颈 —— 因此 TBR 成为移动端 GPU 的主流架构,本质是对硬件限制的最优适配。
片上缓冲的持久性管理
在 TB(D)R 架构下会存储 Tile 的颜色、深度和模板缓冲,读写修改都非常快。如果 Load/Store 指令中缓冲需要被 Preserve,将会被写入一份到 System Memory 中。
在 TB(D)R(基于图块的渲染/延迟渲染)架构中,这句话的核心是解释 "片上缓冲的持久性管理" —— 即当图块渲染过程中产生的颜色、深度、模板缓冲需要被 "保留"(Preserve)时,这些数据会被额外写入系统内存(而非仅存在片上缓存中)。
片上缓冲的默认生命周期
在 TB(D)R 架构中,GPU 会将屏幕分割为多个图块(Tile),每个图块的渲染过程完全依赖片上缓存(如 GMEM 或专用的颜色/深度缓冲缓存):
- 渲染单个图块时,GPU 会在片上缓存中临时存储该图块的颜色缓冲(记录每个像素的颜色值)、深度缓冲(记录像素的深度值,用于遮挡测试)、模板缓冲(记录像素的模板值,用于遮罩等特效);
- 这些缓冲的读写完全在芯片内部完成,速度极快(无需访问外部系统内存),且随着图块渲染完成,默认情况下这些片上缓冲会被释放(数据不再保留),因为图块的最终结果已被拷贝到 FrameBuffer 中,片上空间需要让给下一个图块的渲染。
"缓冲需要被 Preserve" 的含义
"Preserve"(保留)在这里指的是:当前图块渲染产生的颜色、深度或模板缓冲数据,在后续渲染阶段(如其他图块渲染、后处理步骤)中仍需被使用,因此不能随图块渲染结束而释放。
常见需要 "保留缓冲" 的场景包括:
- 多 Pass 渲染:例如,第一遍渲染生成深度缓冲用于 "阴影映射",第二遍渲染需要复用该深度缓冲计算光照;
- 后处理特效:如 HDR 合成、运动模糊、抗锯齿(如 TAA)等,需要读取之前的颜色或深度缓冲数据进行二次计算;
- 跨图块数据依赖:某些特效(如全局雾效)需要多个图块的深度数据联合计算,单个图块的深度缓冲不能即时释放。
写入 System Memory 的原因
既然片上缓冲读写更快,为什么需要把 Preserve 的缓冲写入系统内存?核心原因是片上缓存的容量有限,且需优先服务于实时渲染的图块:
- 片上缓存(如 GMEM)的容量通常较小(移动端 GPU 可能只有几 MB),仅能容纳单个或少数几个图块的缓冲数据;
- 当缓冲需要被 Preserve 时,意味着数据需要 "跨图块" 或 "跨渲染阶段" 存在,而后续图块的渲染会持续占用片上缓存,此时片上空间无法长期保留这些数据;
- 因此,GPU 会通过 Load/Store 指令(加载/存储指令)将需要 Preserve 的缓冲数据 "备份" 到系统内存中 —— Store 指令负责将片上缓冲的数据写入系统内存,后续需要时再通过 Load 指令从系统内存读回片上。
平衡效率与功能需求
TB(D)R 的核心优势是 "片上缓冲减少带宽消耗",但 "Preserve 缓冲写入系统内存" 看似是 "反优化",实则是兼顾功能完整性的必要妥协:
- 正常情况下,片上缓冲随用随弃,最大化减少内存交互;
- 当需要保留数据时,通过写入系统内存确保数据不丢失,虽然增加了少量带宽开销(一次 Store + 后续可能的 Load),但避免了因数据丢失导致的功能失效;
- 相比传统渲染中 "全程依赖系统内存缓冲" 的方式,TB(D)R 仅在 "必须保留" 时才写入系统内存,仍能大幅降低总体带宽(多数场景下缓冲无需保留)。
这句话本质上描述了 TB(D)R 架构中 "缓冲数据的条件性持久化" 机制:片上缓冲默认仅服务于单个图块的实时渲染,随用随弃;当数据需要跨阶段复用时(Preserve),通过 Store 指令写入系统内存以确保可用性,既维持了 TB(D)R 低带宽的核心优势,又满足了复杂渲染场景的功能需求。这也是移动端 GPU 在 "能效优先" 原则下,平衡性能与灵活性的典型设计。
移动端广泛使用 TBR 的原因
- 降低内存带宽需求:移动端设备(如手机、平板)使用的 LPDDR 内存带宽相对桌面级显卡所使用的 GDDR 内存带宽较低。TBR 通过将画面分割成小块,使得在处理每个图块时,大部分数据可以在片上缓存中完成读写操作,只有在图块处理完成后才需要与系统内存进行数据交互。这大大减少了 GPU 与系统内存之间的数据传输量,降低了对内存带宽的要求,从而避免因带宽不足导致的渲染性能瓶颈。例如,在渲染复杂的 3D 游戏场景时,TBR 技术可以有效缓解内存带宽压力,保证游戏画面的流畅性。
- 减少功耗:由于 TBR 减少了 GPU 与系统内存之间的数据传输,而数据在片上缓存中的读写操作功耗要远低于与系统内存之间的交互功耗,所以整体功耗得以降低。对于电池容量有限的移动端设备来说,降低功耗就意味着延长续航时间。比如,在长时间玩游戏或观看视频时,TBR 技术可以使设备的电池消耗更慢。
- 芯片面积和成本优势:TBR 架构使得 GPU 可以利用相对较小的片上缓存来完成渲染任务,而不需要像传统渲染方式那样配备大容量的片上内存来存储整个画面的数据。这有助于在芯片设计时减小 GPU 的面积,从而降低芯片的制造成本,符合移动端设备对成本控制的需求。
- 适合并行处理:移动端 GPU 通常具有多个计算核心(如 ARM Mali 系列 GPU 和苹果自研 GPU),TBR 将画面分割成图块的方式,天然适合多个计算核心并行处理不同的图块,从而提高渲染效率,充分发挥移动端 GPU 的并行计算能力。
此外,还有一种与之相关的技术是 Tile-Based Deferred Rendering(TBDR,基于图块的延迟渲染),它是 TBR 的一种变体,在延迟渲染的基础上结合了图块分割的方式,进一步优化了渲染过程中的性能和功耗表现,在移动端也有广泛应用。
顶点数据与贴图资源的访问
在 GPU 按图块(Tile)顺序渲染时,顶点数据和贴图(纹理)资源并非直接存储在片上缓存(L1、L2 Cache)中,而是通过一套 "外部存储 → 按需加载 → 缓存加速" 的流程被 GPU 访问。这背后的核心逻辑是:片上缓存容量有限,仅用于临时存储计算过程中的中间数据(如像素颜色、深度值),而顶点数据、贴图等 "输入资源" 需长期存储在外部内存中,按需加载到缓存供计算单元使用。
顶点数据和贴图资源的常驻存储位置
顶点数据(如顶点坐标、法线、纹理坐标等)和贴图(纹理)资源属于 "渲染输入资源",其默认存储位置是外部内存(而非片上缓存),具体包括:
- 系统内存(System Memory) :移动端 GPU 通常与 CPU 共享内存(如 LPDDR5),顶点数据和贴图会被加载到这片内存的 "图形专用区域";
- 专用显存(VRAM) :PC 端独立 GPU 有专用显存(如 GDDR6),顶点和纹理资源会优先存储在这里(带宽更高、延迟更低)。
这些资源在渲染前由 CPU 通过驱动程序 "上传" 到外部内存,并被 GPU 识别为可访问的 "资源对象"(如 OpenGL 中的 VBO、纹理对象,Vulkan 中的 Buffer、Image)。
GPU 访问顶点数据的流程
在处理单个图块的顶点阶段(如顶点着色、几何裁剪),GPU 需要读取顶点数据,流程如下:
-
"按需加载":只读取当前图块相关的顶点
TB(D)R 架构的核心优化之一是 "几何阶段的图块相关性裁剪":GPU 会先判断哪些顶点属于当前正在渲染的图块(通过包围盒测试、视锥体裁剪等),只加载这些 "可见顶点" 的数据,而非整个模型的所有顶点。这一步能大幅减少无效数据的传输。 -
"多级缓存" 加速读取
顶点数据从外部内存到计算单元(顶点着色器)的路径为:外部内存 → GPU 内存控制器 → 全局内存(部分架构有,如 NVIDIA 的 Global Memory) → L2 Cache → L1 Cache(顶点着色器专用缓存) → 顶点着色器单元。- L2 Cache 是 GPU 的 "共享缓存",容量较大(如几十 MB),会缓存最近访问的顶点数据(例如相邻图块共享的顶点),减少重复访问外部内存的次数;
- L1 Cache 是顶点着色器的 "私有缓存",容量更小(KB 级),存储当前正在处理的顶点数据,供着色器快速读写(纳秒级延迟)。
-
顶点数据的 "生命周期"
顶点数据被读取后,在片上缓存中仅临时存在:当顶点处理完成(如转换为屏幕坐标、裁剪掉不可见部分),这些原始顶点数据会被标记为 "可替换",缓存空间会让给下一批顶点数据(或其他资源)。
GPU 访问贴图(纹理)资源的流程
贴图(纹理)是像素着色阶段的核心输入(如采样纹理获取像素颜色),其访问流程与顶点数据类似,但依赖 GPU 的 "纹理单元"(Texture Unit)和专用缓存优化:
-
纹理的 "预准备":格式转换与压缩
贴图资源在上传到外部内存时,通常会被转换为 GPU 支持的格式(如 ETC2、ASTC 压缩格式),减少存储体积和带宽消耗。这些压缩纹理会以 "纹理数组" 或 "Mipmap 层级" 的形式存储,方便快速访问不同分辨率的纹理数据。 -
"按需采样":只读取当前像素需要的纹理数据
像素着色器处理图块内的某个像素时,会根据该像素的 "纹理坐标" 计算需要采样的纹理位置(如 Mipmap 层级、纹素坐标)。此时,纹理单元会:- 从外部内存(或 L2 Cache)中读取对应位置的纹理数据(若未缓存);
- 对压缩纹理进行实时解压缩(硬件加速);
- 将解压缩后的纹素数据暂存到纹理缓存(Texture Cache,通常属于 L1 或专用缓存) 中,供像素着色器使用。
-
纹理缓存的 "空间局部性" 优化
由于图块内的像素通常相邻,其采样的纹理区域也具有 "空间局部性"(如相邻像素采样同一纹理的相邻纹素)。纹理缓存会利用这一特性,一次加载 "一片纹理区域"(而非单个纹素),进一步减少外部内存访问次数。
片上缓存是临时计算区,而非资源存储区
总结来说,顶点数据和贴图资源的存储与访问遵循以下原则:
- 存储位置:长期驻留于外部内存(系统内存/显存),因为片上缓存容量太小(MB 级),无法容纳海量的顶点和纹理数据(动辄 GB 级);
- 访问方式:GPU 通过 "按需加载"(只读取当前图块/像素需要的部分)+"多级缓存"(L2→L1/专用缓存)的方式,将资源数据临时载入片上,供计算单元(顶点着色器、像素着色器)快速访问;
- 与片上缓冲的区别:片上缓存(如 L1、L2)中临时存储的顶点/纹理数据,是 "输入资源的副本",用完后可被替换;而图块的颜色、深度缓冲是 "计算的中间结果",仅在当前图块渲染周期内有效(除非被 Preserve)。
这种设计既利用了片上缓存的高速度(加速计算过程),又规避了其容量限制(依赖外部内存存储海量资源),是 GPU 在 "性能 - 带宽 - 成本" 之间的平衡选择,尤其在移动端(带宽和功耗受限)更为关键。
ARM 架构下 Tiled GPU 的渲染流程
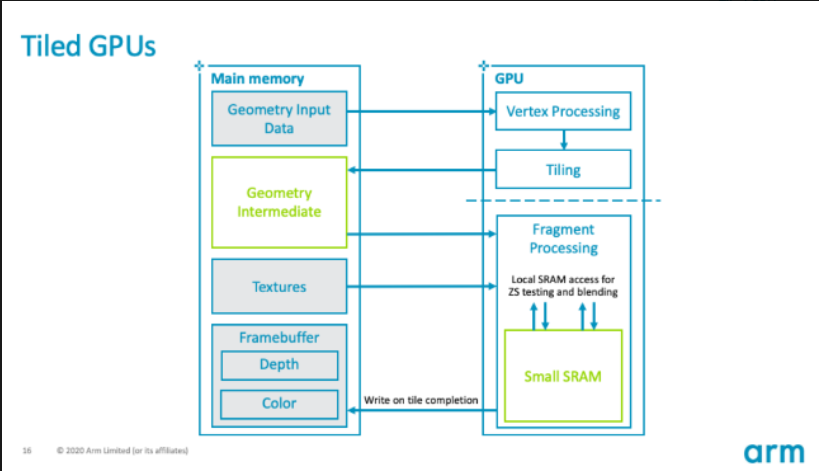
这是 ARM 架构下 Tiled GPU(基于图块渲染的 GPU)的渲染流程示意图,核心展示了 "顶点处理 → 图块划分 → 片上 SRAM 加速片段处理" 的完整逻辑。以下分模块拆解:
系统内存(Main Memory)
-
Geometry Input Data(几何输入数据)
- 存储 3D 模型的原始顶点数据(坐标、法线、纹理坐标等),是 GPU 渲染的 "原材料"。
- 渲染开始时,GPU 从这里读取顶点,进入 "Vertex Processing(顶点处理)" 阶段。
-
Geometry Intermediate(几何中间数据)
- 顶点处理后的 "中间结果"(如变换后的顶点坐标、裁剪后的图元)会暂存到这里。
- 作用:顶点处理和片上渲染分离,避免重复处理顶点,提升效率(比如多个图块共享同一批中间顶点数据)。
-
Textures(纹理数据)
- 存储纹理贴图(如游戏里的皮肤、砖墙纹理),渲染片段(像素)时,GPU 会从这里读取纹理数据,进行采样、着色。
-
Framebuffer(帧缓冲)
- 包含 Depth(深度缓冲,记录像素深度值,用于遮挡测试)和 Color(颜色缓冲,记录最终像素颜色)。
- 注意:图块渲染完成前,Framebuffer 不会被实时写入 → 所有图块的深度、颜色计算都在片上 SRAM 完成,最后才 "Write on tile completion(图块完成时写入)"。
GPU 渲染核心流程
顶点处理与图块划分
- Vertex Processing(顶点处理) :GPU 先对 Geometry Input Data 的顶点进行 "空间变换"(模型空间 → 视图空间 → 裁剪空间)、"顶点着色"(计算顶点颜色、法向量),生成可用于渲染的图元(如三角形)。
- Tiling(图块划分) :把屏幕分割成多个小图块(如 128×128 像素),判断每个图元(如三角形)属于哪些图块 → 只处理 "有图元覆盖" 的图块,跳过空白图块,减少无效计算。
片段处理与片上缓存加速
-
Fragment Processing(片段处理) :对每个图块内的 "片段(像素)" 进行处理,包括:
- 纹理采样(从 Textures 读数据,给像素上色);
- 深度测试(对比 Depth 缓冲,判断像素是否被遮挡);
- 颜色混合(处理半透明、光照等效果)。
-
Small SRAM(片上小容量缓存) :图块的所有片段处理都在这片 SRAM 内完成 → 深度、颜色缓冲临时存在 SRAM,无需实时访问外部 Framebuffer,大幅降低带宽和延迟!
- 优势:SRAM 是片上高速缓存,读写速度远快于外部内存 → 图块内的片段处理效率拉满。
- 限制:容量小,只能存单个/少数图块的数据 → 必须 "一个图块处理完,再处理下一个"。
Tiled Rendering 的延迟写入优势
- 传统渲染:片段处理时,频繁读写外部 Framebuffer → 带宽高、延迟大、耗电快。
- Tiled GPU:所有图块的深度、颜色计算都在片上 SRAM 完成 → 只有图块渲染完毕,才一次性写入外部 Framebuffer → 带宽需求砍半,功耗/延迟暴降。
这就是移动端 GPU(如 ARM Mali 系列)普遍用 Tiled Rendering 的原因 —— 用片上 SRAM 换带宽和功耗,适配手机、平板等 "低功耗 + 高性能" 需求。
这张图完整展示了 ARM Tiled GPU 的渲染流程:顶点处理 → 划分图块 → 片上 SRAM 加速片段计算 → 最后写入帧缓冲。核心是通过 "图块 + 片上缓存",解决移动端带宽不足、功耗敏感的痛点,让 GPU 渲染又快又省电~
GPU 渲染流程的硬件数据流
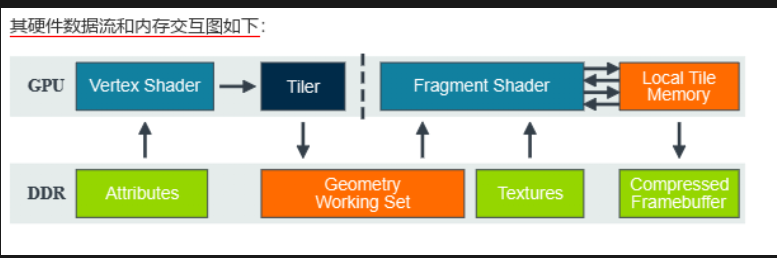
这是基于图块渲染(Tiled Rendering)架构的 GPU 渲染流程,核心展示 "顶点 → 图块 → 片段(像素)" 的渲染数据流动:
模块拆解
-
GPU 侧(上半部分)
- Vertex Shader(顶点着色器) :处理顶点数据(如坐标变换、顶点颜色计算),是 3D 渲染的第一步。
- Tiler(图块划分单元) :把屏幕分割为小图块,标记哪些图块包含几何数据,决定后续片段处理的范围(只处理有内容的图块,减少无效计算)。
- Fragment Shader(片段着色器) :处理每个图块内的像素(如纹理采样、颜色混合),决定最终像素颜色。
- Local Tile Memory(片上图块内存) :图块渲染时的 "临时缓存",存储当前图块的深度、颜色等中间数据(替代直接读写外部帧缓冲,降低带宽)。
-
DDR 侧(下半部分,外部内存)
- Attributes(属性数据) :存储顶点的基础属性(如坐标、法线),供 Vertex Shader 读取。
- Geometry Working Set(几何工作集) :顶点处理后的中间数据(如裁剪后的图元),供 Tiler 判断图块归属。
- Textures(纹理数据) :存储纹理贴图(如游戏中的皮肤、场景纹理),供 Fragment Shader 采样。
- Compressed Framebuffer(压缩帧缓冲) :最终渲染结果的存储区,图块处理完成后,数据会压缩写入这里(降低带宽需求)。
CPU-GPU 交互逻辑
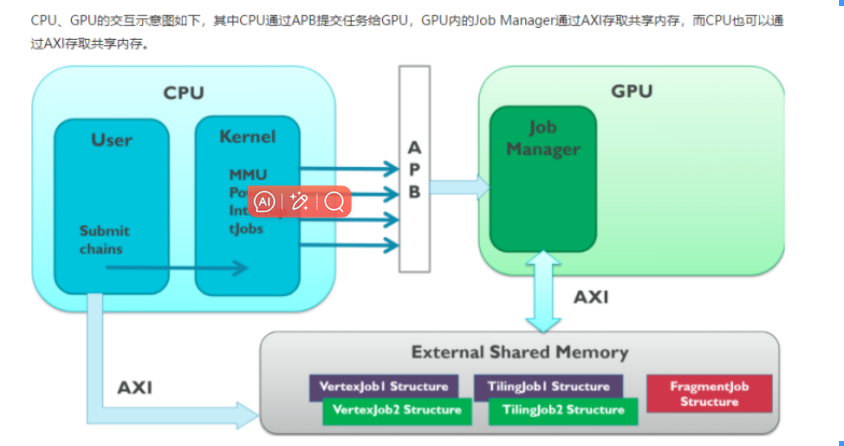
这是 CPU 与 GPU 如何通过总线(AXI)协同、调度任务的架构,核心展示 "CPU 发任务 →GPU 执行 → 共享内存交互" 的逻辑:
模块拆解
-
CPU 侧(左侧)
-
User(用户空间) :应用程序(如游戏、视频软件)通过 "Submit chains(提交链)" 向 GPU 发任务(如 "渲染一帧画面")。
-
Kernel(内核空间) :操作系统内核通过 AXI 总线 管理 GPU 资源,包括:
- MMU(内存管理单元) :控制内存访问权限,确保 CPU/GPU 安全共享内存。
- Power(电源管理) :调节 GPU 功耗(如高负载时提频,低负载时降频)。
- Interrupt(中断) :GPU 任务完成后,通过中断通知 CPU(如渲染完一帧,通知 CPU 准备下一帧)。
- Jobs(任务队列) :把用户空间的任务转化为 GPU 可执行的指令,通过 AXI 发给 GPU。
-
-
GPU 侧(右侧)
- Job Manager(任务管理器) :接收 CPU 发来的任务,调度 GPU 内部资源(如顶点着色器、片段着色器)执行渲染,同时通过 AXI 读写共享内存。
-
中间层
- AXI(总线协议) :CPU 与 GPU 通信的 "数据高速公路",负责传输任务指令、内存地址、渲染数据。
- External Shared Memory(外部共享内存) :CPU 与 GPU 共享的内存区域,存储任务参数、顶点数据、纹理、帧缓冲等(如 OpenGL 的 VBO、纹理对象都存这里)。
两张图的关联
-
数据流动闭环:第二张图的 CPU 通过 AXI 把 "渲染任务" 发给 GPU → 第一张图的 GPU 启动 Vertex Shader、Tiler、Fragment Shader 处理数据 → 渲染所需的顶点、纹理存在 "共享内存"(第二张图的 External Shared Memory 对应第一张图的 DDR 侧资源) → 最终结果写回共享内存,供 CPU 显示或进一步处理。
-
设计目标:两张图共同体现 "低带宽、高协同" 的移动端 GPU 设计:
- 第一张图用 "图块渲染 + 片上缓存" 减少内存访问;
- 第二张图用 "AXI 总线 + 共享内存" 让 CPU/GPU 高效协同,最终实现 "高性能渲染 + 低功耗"(适配手机、平板等移动设备)。
Unity 中 RenderBuffer Load/Store Action
作用
RenderBufferLoadAction 与 RenderBufferStoreAction 是 Unity setRenderTarget 方法中控制渲染缓冲(颜色、深度、模板缓冲)加载/存储行为的 API,用于适配 "缓冲是否需要 Preserve" 的需求。
RenderBufferLoadAction(渲染开始时的操作)
- Load:加载缓冲中已有的数据(用于复用之前保留的数据,如多 Pass 渲染中加载深度缓冲)。
- Clear:清除缓冲数据(设置为默认值,如黑色、深度最大值,确保渲染起点干净)。
- DontCare:不关心缓冲原有数据(GPU 可自由处理,节省加载开销,适用于无需复用的临时缓冲)。
RenderBufferStoreAction(渲染结束时的操作)
- Store:将当前渲染结果存储到缓冲中(用于需要 Preserve 的场景,确保后续阶段可复用)。
- DontCare:不保留缓冲数据(用完即弃,节省存储开销,适用于临时中间缓冲)。
Preserve 需求与 API 设置的对应
-
当缓冲需要 Preserve(跨阶段复用):
- 前序阶段需设置
StoreAction = Store(保留数据到缓冲); - 后续阶段需设置
LoadAction = Load(加载复用该数据)。
- 前序阶段需设置
-
当缓冲无需 Preserve:
- 可设置
StoreAction = DontCare(节省存储)和LoadAction = Clear/DontCare(无需加载)。
- 可设置
常见问题
- 前序未用 StoreAction,后续用 LoadAction 的风险:前序未设置
StoreAction = Store 时,缓冲数据可能被丢弃或处于未定义状态(随机值/默认值),后续LoadAction = Load会加载无效数据,导致渲染错误(如阴影异常、后处理失效)。 - 例外情况:部分平台/GPU 可能隐含保留规则,但属于未定义行为,不可依赖。
规范用法
- 需跨阶段复用的数据,必须显式用
StoreAction = Store 保留,再用LoadAction = Load加载。 - 临时缓冲(无需复用)用
DontCare减少带宽/功耗开销。
核心原则:数据复用依赖显式保留(Store),否则后续加载(Load)无效,这是保证渲染正确性和性能的关键。