
顶点着色器
顶点着色器处理每个传入的顶点。它接收其属性(如模型空间位置、颜色、法线和纹理坐标)作为输入。输出是剪裁坐标中的最终位置以及需要传递给片段着色器的属性(如颜色和纹理坐标)。然后这些值将通过光栅化器在片段之间进行插值,以产生平滑的渐变。
剪裁坐标是来自顶点着色器的四维向量,随后通过将整个向量除以其最后一个分量转换为归一化设备坐标。这些归一化设备坐标是齐次坐标,将帧缓冲映射到 [-1, 1] × [-1, 1] 坐标系,如下所示:

如果你以前使用过 OpenGL,你会注意到 Y 坐标的符号现在是翻转的。Z 坐标现在与 Direct3D 一样使用相同的范围,从 0 到 1。
对于我们的第一个三角形,我们不会应用任何变换,我们将直接指定三个顶点的位置作为归一化设备坐标来创建以下形状:
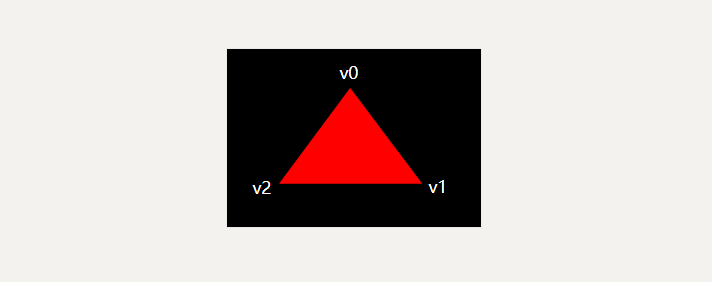
我们可以通过从顶点着色器输出它们作为剪裁坐标(并将最后一个分量设置为 1)来直接输出归一化设备坐标。这样,变换剪裁坐标为归一化设备坐标的除法不会改变任何东西。
通常这些坐标会存储在顶点缓冲中,但在 Vulkan 中创建顶点缓冲并用数据填充它并非易事。因此我决定推迟这一步,等到我们看到三角形渲染到屏幕上获得满足感之后再处理。与此同时,我们将做一些不太常规的事情:将坐标直接硬编码在顶点着色器中。代码如下:
#version 450
vec2 positions[3] = vec2[](
vec2(0.0, -0.5),
vec2(0.5, 0.5),
vec2(-0.5, 0.5)
);
void main() {
gl_Position = vec4(positions[gl_VertexIndex], 0.0, 1.0);
}
main 函数对每个顶点调用一次。内置变量 gl_VertexIndex 包含当前顶点的索引。这通常是顶点缓冲的索引,但在我们的案例中它将是对硬编码顶点数据数组的索引。每个顶点的位置从着色器中的常量数组访问,并与额外的 z 和 w 分量组合以产生剪裁坐标中的位置。内置变量 gl_Position 作为输出。
片段着色器
由顶点着色器中的位置形成的三角形在屏幕上覆盖一个区域。片段着色器对这些片段调用,以产生帧缓冲的颜色和深度(或多个帧缓冲)。一个简单的片段着色器为整个三角形输出红色的示例如下:
#version 450
layout(location = 0) out vec4 outColor;
void main() {
outColor = vec4(1.0, 0.0, 0.0, 1.0);
}
main 函数对每个片段调用,就像顶点着色器 main 函数对每个顶点调用一样。GLSL 中的颜色是四分量向量,R、G、B 和 alpha 通道在 [0, 1] 范围内。与顶点着色器中的 gl_Position 不同,没有内置变量来为当前片段输出颜色。你必须为每个帧缓冲指定你自己的输出变量,其中 layout(location = 0) 修饰符指定帧缓冲的索引。红色被写入这个链接到索引 0 的第一个(也是唯一一个)帧缓冲的 outColor 变量。
逐顶点颜色
让整个三角形变红不是很有趣,像下面这样的不是更好看吗?
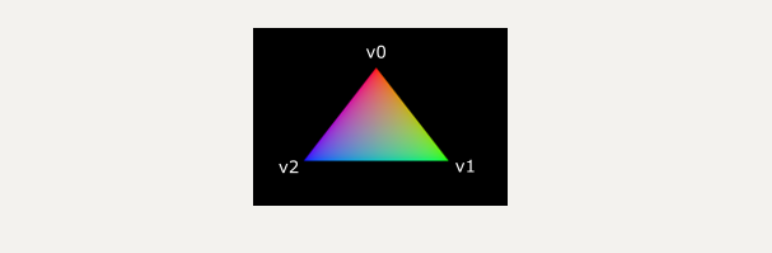
我们必须对两个着色器进行一些更改来完成这个。首先,我们需要为三个顶点中的每一个指定一个独特的颜色。顶点着色器现在应该包含一个颜色数组,就像它为位置所做的那样:
vec3 colors[3] = vec3[](
vec3(1.0, 0.0, 0.0),
vec3(0.0, 1.0, 0.0),
vec3(0.0, 0.0, 1.0)
);
现在我们只需要将这些逐顶点颜色传递给片段着色器,以便它可以将它们的插值输出到帧缓冲。在顶点着色器中添加一个颜色输出,并在 main 函数中写入:
layout(location = 0) out vec3 fragColor;
void main() {
gl_Position = vec4(positions[gl_VertexIndex], 0.0, 1.0);
fragColor = colors[gl_VertexIndex];
}
接下来,我们需要在片段着色器中添加一个匹配的输入:
layout(location = 0) in vec3 fragColor;
void main() {
outColor = vec4(fragColor, 1.0);
}
输入变量不一定使用相同的名称,它们将通过 location 指令指定的索引链接在一起。main 函数已更改为输出颜色以及 alpha 值。如上图所示,fragColor 的值将自动在三个顶点之间的片段之间进行插值,产生平滑的渐变。
编译着色器
在你的项目根目录中创建一个名为 shaders 的目录,并将顶点着色器存储在该目录中名为 shader.vert 的文件中,将片段着色器存储在名为 shader.frag 的文件中。GLSL 着色器没有官方扩展名,但这两个常用于区分它们。
shader.vert 的内容应该是:
#version 450
layout(location = 0) out vec3 fragColor;
vec2 positions[3] = vec2[](
vec2(0.0, -0.5),
vec2(0.5, 0.5),
vec2(-0.5, 0.5)
);
vec3 colors[3] = vec3[](
vec3(1.0, 0.0, 0.0),
vec3(0.0, 1.0, 0.0),
vec3(0.0, 0.0, 1.0)
);
void main() {
gl_Position = vec4(positions[gl_VertexIndex], 0.0, 1.0);
fragColor = colors[gl_VertexIndex];
}
而 shader.frag 的内容应该是:
#version 450
layout(location = 0) in vec3 fragColor;
layout(location = 0) out vec4 outColor;
void main() {
outColor = vec4(fragColor, 1.0);
}
我们现在将使用 glslc 程序将这些编译为 SPIR-V 字节码。
Windows
创建包含以下内容的 compile.bat 文件:
C:/VulkanSDK/x.x.x.x/Bin/glslc.exe shader.vert -o vert.spv
C:/VulkanSDK/x.x.x.x/Bin/glslc.exe shader.frag -o frag.spv
pause
将 glslc.exe 的路径替换为你安装 Vulkan SDK 的路径。双击文件运行它。
Linux
创建包含以下内容的 compile.sh 文件:
/home/user/VulkanSDK/x.x.x.x/x86_64/bin/glslc shader.vert -o vert.spv
/home/user/VulkanSDK/x.x.x.x/x86_64/bin/glslc shader.frag -o frag.spv
将 glslc 的路径替换为你安装 Vulkan SDK 的路径。使用 chmod +x compile.sh 使脚本可执行并运行它。
平台特定说明结束
这两个命令告诉编译器读取 GLSL 源文件并使用 -o(输出)标志输出 SPIR-V 字节码文件。
如果你的着色器包含语法错误,编译器会告诉你行号和问题,正如你所期望的那样。例如,尝试故意遗漏一个分号并再次运行编译脚本。也尝试不带任何参数运行编译器以查看它支持什么样的标志。例如,它还可以将字节码输出为人类可读的格式,以便你可以准确了解你的着色器在做什么以及此阶段应用了哪些优化。
在命令行编译着色器是最直接的选项之一,这是我们在本教程中使用的,但也可以直接从你自己的代码中编译着色器。Vulkan SDK 包含 libshaderc,它是一个库,可以从你的程序内部将 GLSL 代码编译为 SPIR-V。
加载着色器
数据流:shaders/vert.spv(磁盘文件)── readFile() ──▶ std::vector<char>(内存)
现在我们有了生成 SPIR-V 着色器的方法,接下来将它们加载到程序中,稍后用于构建图形管线。首先编写一个简单的辅助函数来从文件加载二进制数据。
#include <fstream>
...
static std::vector<char> readFile(const std::string& filename) {
// ate: 打开时定位到文件末尾 | binary: 二进制模式,避免文本转换
std::ifstream file(filename, std::ios::ate | std::ios::binary);
if (!file.is_open()) {
throw std::runtime_error("failed to open file!");
}
// ate 模式下,tellg() 直接返回文件大小
size_t fileSize = (size_t) file.tellg();
std::vector<char> buffer(fileSize); // 按大小分配缓冲
file.seekg(0); // 回到文件开头
file.read(buffer.data(), fileSize); // 一次读完所有字节
file.close();
return buffer;
}
readFile 函数从指定文件读取所有字节,返回由 std::vector 管理的字节数组。我们用两个标志打开文件:
-
ate:从文件末尾开始读取 -
binary:将文件作为二进制文件读取(避免文本转换)
使用 ate 标志的优势在于:文件打开时读取位置已在末尾,因此可以直接用 tellg() 获取文件大小,然后分配缓冲:
为什么用 ate?
普通方式:打开 → seek 到末尾 → tellg 获取大小 → seek 回开头 → 读
ate 方式: 打开(已在末尾)→ tellg 获取大小 → seek 回开头 → 读 ← 少一步
size_t fileSize = (size_t) file.tellg();
std::vector<char> buffer(fileSize);
之后,我们可以回到文件开头并一次读取所有字节:
file.seekg(0);
file.read(buffer.data(), fileSize);
最后关闭文件并返回字节:
file.close();
return buffer;
我们现在将从 createGraphicsPipeline 调用此函数来加载两个着色器的字节码:
void createGraphicsPipeline() {
auto vertShaderCode = readFile("shaders/vert.spv");
auto fragShaderCode = readFile("shaders/frag.spv");
}
可以打印缓冲的大小并与实际文件大小(以字节为单位)对比,以确认着色器加载正确。注意,这里的二进制数据不需要以空字符结尾,因为我们会在后续步骤中明确指定其大小。
创建着色器模块
数据流:std::vector<char>(字节码)── createShaderModule() ──▶ VkShaderModule(Vulkan 对象)
在我们可以将代码传递给管线之前,我们必须将其包装在 VkShaderModule 对象中。让我们创建一个辅助函数 createShaderModule 来做到这一点。
VkShaderModule createShaderModule(const std::vector<char>& code) {
}
该函数接收字节码缓冲作为参数,并从中创建一个 VkShaderModule。
创建着色器模块很简单,只需指定字节码的缓冲指针及其长度,这些信息在 VkShaderModuleCreateInfo 结构体中指定。需要注意一点:codeSize 以字节为单位,但 pCode 是 uint32_t* 而非 char*,因此需要用 reinterpret_cast 做指针转换。之所以安全,是因为 std::vector 的默认分配器保证了内存满足最严格的对齐要求,uint32_t 对齐自然也不在话下。
VkShaderModuleCreateInfo createInfo{};
createInfo.sType = VK_STRUCTURE_TYPE_SHADER_MODULE_CREATE_INFO;
createInfo.codeSize = code.size(); // 字节数
createInfo.pCode = reinterpret_cast<const uint32_t*>(code.data()); // char* → uint32_t*
然后可以使用 vkCreateShaderModule 调用创建 VkShaderModule:
VkShaderModule shaderModule;
if (vkCreateShaderModule(device, &createInfo, nullptr, &shaderModule) != VK_SUCCESS) {
throw std::runtime_error("failed to create shader module!");
}
参数与之前的对象创建函数一致:逻辑设备、创建信息结构体指针、可选的自定义分配器以及句柄输出变量。包含字节码的缓冲可以在着色器模块创建后立即释放。最后别忘了返回创建好的着色器模块:
return shaderModule;
着色器模块只是对我们之前从文件加载的着色器字节码和其中定义的函数的一个轻量包装。SPIR-V 字节码编译并链接为 GPU 可执行的原生代码,要等到图形管线创建时才会发生。这意味着我们可以在管线创建完成后立即销毁着色器模块,这就是为什么我们将它们作为 createGraphicsPipeline 函数中的局部变量而不是类成员来声明。
着色器模块生命周期:
readFile() createShaderModule() 创建图形管线 vkDestroyShaderModule()
读入字节码 ──▶ 包装为 VkShaderModule ──▶ 真正编译链接 ──▶ 立即销毁模块
(模块只是临时包装)
void createGraphicsPipeline() {
auto vertShaderCode = readFile("shaders/vert.spv");
auto fragShaderCode = readFile("shaders/frag.spv");
VkShaderModule vertShaderModule = createShaderModule(vertShaderCode); // 局部变量,不是类成员
VkShaderModule fragShaderModule = createShaderModule(fragShaderCode);
然后应在函数末尾添加两个 vkDestroyShaderModule 调用来执行清理。本章后续的所有代码都将插入到这两行之前。
...
vkDestroyShaderModule(device, fragShaderModule, nullptr);
vkDestroyShaderModule(device, vertShaderModule, nullptr);
}
着色器阶段创建
数据流:VkShaderModule(着色器代码)── 分配阶段 ──▶ VkPipelineShaderStageCreateInfo(管线阶段描述)
要实际使用着色器,我们需要通过 VkPipelineShaderStageCreateInfo 结构体将着色器模块分配到管线的特定阶段,这是管线创建过程的一部分。
我们首先在 createGraphicsPipeline 函数中填充顶点着色器的结构体。
VkPipelineShaderStageCreateInfo vertShaderStageInfo{};
vertShaderStageInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_SHADER_STAGE_CREATE_INFO;
vertShaderStageInfo.stage = VK_SHADER_STAGE_VERTEX_BIT; // 管线阶段:顶点
除了必需的 sType 成员外,第一步是告诉 Vulkan 着色器将在哪个管线阶段使用。上一章描述的每个可编程阶段都有一个枚举值。
vertShaderStageInfo.module = vertShaderModule; // 着色器模块
vertShaderStageInfo.pName = "main"; // 入口函数名
接下来的两个成员分别指定着色器模块和入口点函数。入口点意味着可以将多个着色器组合到同一个模块中,通过不同的入口函数区分行为。这里我们使用标准的 main。
三个关键字段:
| 字段 | 含义 | 示例 |
|---|---|---|
stage |
管线中的哪个阶段 | VERTEX_BIT / FRAGMENT_BIT |
module |
哪个着色器模块 | vertShaderModule / fragShaderModule |
pName |
着色器中的入口函数 | "main"(可用不同入口点区分同一模块中的多个着色器) |
还有一个可选成员 pSpecializationInfo,我们不会在这里使用,但值得了解。它允许你在管线创建时为着色器常量指定值,相当于用单个着色器模块配合不同的常量值来配置行为。这比在渲染时用变量控制更高效,因为编译器可以据此消除 if 分支等死代码。如果没有这类常量,将该成员设为 nullptr 即可,我们的结构体初始化已经自动做了这一点。
对应的片段着色器结构体只需稍作修改:
VkPipelineShaderStageCreateInfo fragShaderStageInfo{};
fragShaderStageInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_SHADER_STAGE_CREATE_INFO;
fragShaderStageInfo.stage = VK_SHADER_STAGE_FRAGMENT_BIT; // 管线阶段:片段
fragShaderStageInfo.module = fragShaderModule; // 着色器模块
fragShaderStageInfo.pName = "main"; // 入口函数名
最后定义一个数组包含这两个结构体,后续在实际创建管线时将通过它来引用这两个着色器阶段。
VkPipelineShaderStageCreateInfo shaderStages[] = {vertShaderStageInfo, fragShaderStageInfo};